048-711-7195
107-0062 東京都港区南青山2-2-15-942
月~金 9:00~18:00
重回帰分析ではサンプル店舗を削ってはいけません
売上予測をエクセルで極める その92 重回帰分析 分析ポイント(7)サンプル店舗は統計的にうまく絞ること 冒頭にあったように、百~数百店舗を有しているチェーン店の場合は、30~40サンプルくらいに店舗を絞る必要があります。 この場合の絞り方は重要です。単に、行動範囲を短くして効率的に調査できるようにしようと近い店同士を選んだり、面積が似通っている店だけ選んだりというのは避けた方が良いでしょう。 最もお勧めの絞り方は、ランダムに選ぶことです。そして、その上で、全店における売上の平均値と標準偏差という統計値、絞ったサンプルにおけるそれらの統計値がなるべく似通っていることです。
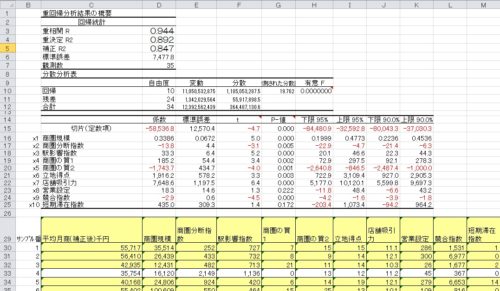
分析ポイント(8)サンプル店舗を削ってはいけない 重回帰分析をすすめていくと、必ず1つや2つどうしても、残差が大きいままで、合理的な立地要因が見つからないというサンプルが出てくるものです。そうすると、データの改変はしないものの、そのサンプル自体を削ってしまう人が出てきます。 これも間違っています。すでに書いたように、今見つからないからといって、何らかの要因は必ずあるはずです。だから、残差が出ているわけで、これは、新発見の前段階かもしれないのです。ですから、取り除いてしまってはいけません。 どうしても、こういう大きな残差が残っているのが感覚的に受け入れられないというのであれば、「D店指数(仮称)」という説明変数を作って加えることです。この指数は、残差の大きいD店だけに「1」というデータを入れ、他のサンプルはすべて「0」にしておくものです。こういう変数をダミー変数と言いますが、この変数を入れることで、「大きな残差」は消えます。もちろん、原因が見つかったわけではありませんので、後日、調べなければなりません。
23/06/12
22/05/20
21/12/30
21/08/04
21/08/03
21/08/01
21/07/31
21/07/10
21/07/09
21/07/08
TOP


売上予測をエクセルで極める その92 重回帰分析
分析ポイント(7)サンプル店舗は統計的にうまく絞ること
冒頭にあったように、百~数百店舗を有しているチェーン店の場合は、30~40サンプルくらいに店舗を絞る必要があります。
この場合の絞り方は重要です。単に、行動範囲を短くして効率的に調査できるようにしようと近い店同士を選んだり、面積が似通っている店だけ選んだりというのは避けた方が良いでしょう。
最もお勧めの絞り方は、ランダムに選ぶことです。そして、その上で、全店における売上の平均値と標準偏差という統計値、絞ったサンプルにおけるそれらの統計値がなるべく似通っていることです。
分析ポイント(8)サンプル店舗を削ってはいけない
重回帰分析をすすめていくと、必ず1つや2つどうしても、残差が大きいままで、合理的な立地要因が見つからないというサンプルが出てくるものです。そうすると、データの改変はしないものの、そのサンプル自体を削ってしまう人が出てきます。
これも間違っています。すでに書いたように、今見つからないからといって、何らかの要因は必ずあるはずです。だから、残差が出ているわけで、これは、新発見の前段階かもしれないのです。ですから、取り除いてしまってはいけません。
どうしても、こういう大きな残差が残っているのが感覚的に受け入れられないというのであれば、「D店指数(仮称)」という説明変数を作って加えることです。この指数は、残差の大きいD店だけに「1」というデータを入れ、他のサンプルはすべて「0」にしておくものです。こういう変数をダミー変数と言いますが、この変数を入れることで、「大きな残差」は消えます。もちろん、原因が見つかったわけではありませんので、後日、調べなければなりません。