「売上予測の奥義 高精度/売上予測モデルの作り方」
048-711-7195
107-0062 東京都港区南青山2-2-15-942
月~金 9:00~18:00
048-711-7195
107-0062 東京都港区南青山2-2-15-942
月~金 9:00~18:00

「売上予測の奥義 高精度/売上予測モデルの作り方」


1)「立地」を「数字」に変える売上予測
2)平均予測法、一番簡単な売上予測
平均予測法のルール1
平均予測法のルール2
平均予測法のルール3
3)少し確かな売上予測の方法(1)、回転率法
本当にあった回転率法を使った売上予測
次のような疑問が出て来ませんでしたか?
4)少し確かな売上予測の方法(2)キャッチ率法
① 計測地点の問題
②計測対象の問題
➂ 計測時の問題
5)少し確かな売上予測の方法(3)市場シェア率法
①どれだけ市場(マーケット)規模があるか
②どれだけシェアがとれるか
6)少し確かな売上予測の方法(4)、範囲限定法
ステップ1 最小の値と最大の値を決める
ステップ2 最小より良い点を見つける。
ステップ3 最大より問題となる点を見つける。
ステップ4 他の店との比較も試みる
ステップ5 自分の出した結論に間違いがないかチェックする。
7)明日はいくら売れるのか、時系列売上予測
売上予算は、時系列売上予測
EPA法による売上予測
8)比較法で計算する、売上予測の基本
Step1.既存店を選ぶ
Step2.立地要因をリストアップする。
Step3.既存店それぞれに、立地要因の点数をつける
Step4.それぞれの立地要因に、ウェイトを与える。
Step5.既存店の店舗別に、立地得点を付ける。
Step6.立地得点と売上との関係式(係数)を求める。
Step7.予測対象物件の立地得点を出し、売上予測する。
9)本格的に売上予測をする、重回帰分析
注意点、心構え。
チェーン企業内での役割
売上予測をする人の3つの資格
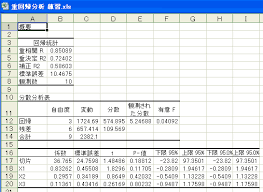
10)重回帰分析による売上予測のやり方
手順1 データ表を作成する
手順2 目的変数(売上)を決める
手順3 説明変数の骨を作る
手順4 理論値を出し、残差を求める。
手順5 第二説明変数を見つける
手順6 重回帰ソフトの設定と実行
手順7 理論値を出し、残差を求め、
以降これを繰り返す。
11)重回帰分析の落とし穴
(1)サンプル数は少ないところからはじめる。
(2)データには必ずミスが入り込む。
(3)内部相関の高いデータは使わない
(4)説明変数は少ないほど良い。
(5)後からデータを無根拠に改変するのはNG
(6)まずは、常識をきかせること
(7)サンプル店舗は統計的にうまく絞ること
(8)サンプル店舗を削ってはいけない
(9)相関係数に拘り過ぎない
(10)コンピュータ(ソフトウェア)に任せきりにしない
12)変数の作り方
(1)目的変数の求め方
(2)競合変数の求め方
(3)立地指数の求め方
(4)残差分析
(5)分類
「駅前の1等地だから(立地が良い)」、
「店前通行量が1万人以上あるから(立地は)だいじょうぶ」、
「○○スーパーの出入り口から良く見えるから(立地が良い)」・・・
こういう常套句が、
出店するかどうかの決め手になっている個人、チェーン企業は多いと思います。
特に、 2番目の通行量は、車の交通量と合わせて ひんぱんに説得材料として使われています。
しかも、たいへん昔から 「立地の定石」のように扱われてきました
(余談ですが、今でも、フランチャイズ本部を加盟店側が裁判に訴えたとき、
「本部は通行量調査さえしてくれなかった」
と主張することがあります。、
すると、裁判所はこの主張を ”支持”して、本部が怠慢であったと判定を下します。
立地については、まったくの門外漢である裁判所でさえ通行量は重要と思ってしまうほど、一般的には、通行量は大事だと思われています)。
もちろん、
賢い個人・チェーン企業は、単一の立地要因だけを決め手にしていることはないでしょう。
むしろ、
チェックリストを用意して、 数十項目以上のチェックを行って、得点化し
「総合得点」を出していることのほうが多いかもしれません。
しかし、立地は立地、立地のこの要因が良い、この要因は良くない、こちらの要因は・・・
のように立地にまつわる
どんな要因をチェックしてみたところで、
それだけでは、 まったく意味がないことのほうが多いのです。
もっと言うと、
チェックリストを使って、 立地の総合得点が良かったとしましょう。
「だからなに?売れるの?売れないの?」 と質問されたら
答えに窮するのが、実態です。
多くのチェーン企業は「立地判定チェックリスト」 を作っています。
表1~表3のようなチェックリストでも無いよりはましだから、使っています。
でも、いつのときでも、「このチェックリストさえあれば万事うまく行きます」と言うわけではありません。

「平均予測法」
は客観的で誰もができる方法ですが、
決して高い精度の予測が できるわけではありません。
ただ、他の予測法の精度についてその高さを比較する基準にはなります。
では、もっと「正確に」売上予測を行うにはどうしたら良いでしょう?
古くから飲食業などで用いられている売上予測に、
「回転率法」
があります。
この方法は、
「客席数」を元に売上を予測するものです。
1日に客席が
お客様で何回使われるかを求めます。
これを、 回転率と言います。
例えば、客席が25席あって、来客数が50人であれば、
回転率は 50÷25=2回転となります。
予測に際してはこの回転率を いくつにするかがポイントです。

コンピュータを駆使して、
新店の「売上予測」を行っていく方法
を説明しましょう。
コンピュータと言えば、難しそうに思えるかもしれませんが、
エクセルなどの 表計算ソフトを使ったことのある人なら、容易にわかるはずです。
もし、
扱ったことがなければ、この機会に、コンピュータに慣れ親しんでください。
まず、手始めに
「比較法」での売上予測をやってみましょう。
簡単に、概略を書きますと、
「既存店の立地を 数値化したものを元に、 立地得点 と 係数
を求め、
新店の立地得点を用いて 売上予測するもの」です。
その順番を具体的に書くと次のようになります。
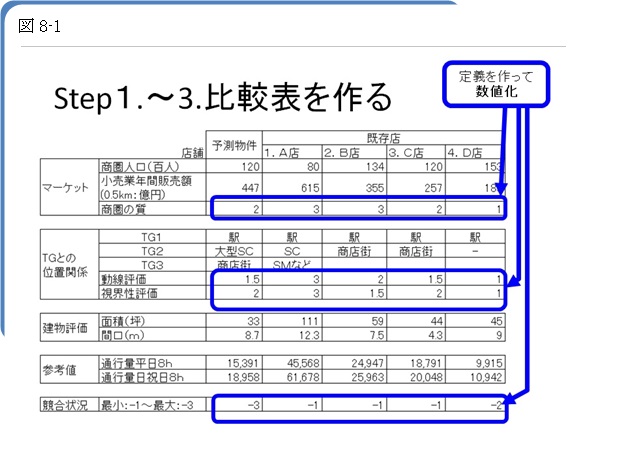
Step1.既存店を選ぶ
Step2.立地要因をリストアップする。
Step3.既存店それぞれに、立地要因の点数をつける
Step4.それぞれの立地要因に、ウェイトを与える
Step5.既存店の店舗別に、立地得点を付ける
Step6.立地得点と売上との関係式(係数)を求める
Step7.予測対象物件の立地得点を出し、売上予測する。
この7つのステップで、予測ができます。
ちょっとしたコツさえつかめば、誰でも簡単に、
売上予測をすることができるので、
初心者向けにはとても良い練習になります。
それでは、それぞれのステップについて、詳しく説明していきましょう。
比較法を行うためには、
既存店が4店舗以上あり、
それぞれの月間売上が6か月以上ある
ことが必要です。
仮に、
それより少ないような場合は、
同業他社の店であっても構いません。
ただし、
既存店同様、月間売上がわかっていなければなりません。
売上でなく客数でも構いません。
6か月というのは、最初の数か月間は、開店景気で売上が通常より良かったり、
あるいは逆に、
認知が浸透していないため悪かったりする場合がありますので、
この期間を除いて 月間売上の平均を求めるためです。
ですから、
仮に データが1か月分しかない場合でも、
この補正ができるようなら、それで十分です。
また、
既存店が多くて、数十店ある場合では、
その一部、10店舗程度を用いれば良いでしょう。
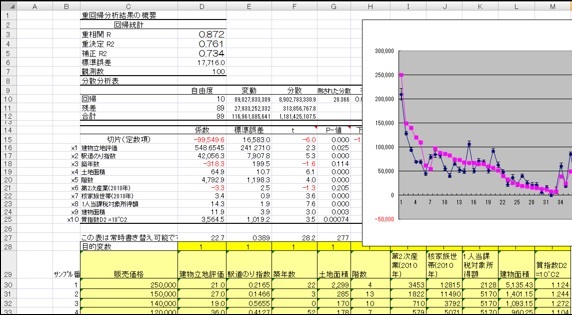
重回帰分析(じゅうかいきぶんせき)
による売上予測の方法は、
まず既存店の立地を調査して、立地と売上についての関係式
(これを「モデル」と呼びます)
を作ります。
この関係式に、必要な立地データを入力して、売上を予測するというものです。
では、順を追って説明していきます。
まず、
関係式のことについて、知ってもらわなければなりません。
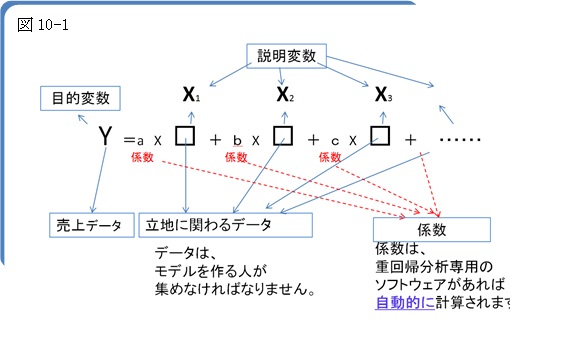
この関係式とは、
Y=a×X1+b×X2+・・・
のように、
多項式で表わされます。
一般的には、
Yは目的変数、
X1、X2・・は説明変数と言われますが、
ここでは、
Yには売上データ、
X1、X2・・には立地に関わるデータ、
例えば、
商圏人口とか、
視界性評価等が入ります(図10-1)。
重回帰分析という
データをたくさん処理できる手法は、
とても便利でパソコンを用いると簡単に操作できるので
最近は多くの専門分野で、世界中で使われるようになってきています。
しかし、
最初にチャレンジする人にとって馴染みが薄いことや
専門書にもあまり書いていないこともあって、
誤った使い方、分析の仕方を行っていることが往々にしてあります。
そこで、ここでは、
このモデルを作るにあたって多くの人が陥りやすい落とし穴
を分析ポイントとして解説していきます。
売上予測は、精度が命です。
誤った作り方をすれば、精度どころの話ではなくなってしまいます
ですからよくよく理解していただきたいと思います。
分析ポイント
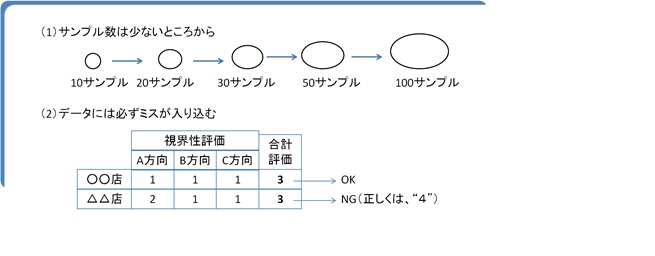
サンプルが多ければ多いほど良い。
だからといって
数百サンプル(店)を最初から調べようとする人がいます。
これは、統計解析を少しかじったことがある人が多く陥る罠です。
確かに、理論上はこの通りなのです。
10サンプル(10店舗)でモデルを作るより、
20サンプル、30サンプルで作った方が高い精度の売上予測モデルを作ることができます。
しかし、だからといって、
最初から100サンプル、あるいは全店300サンプルを使って
モデルを作ろうとするのは実践的ではありません。
業種業態によって、良い立地、悪い立地というのは微妙に、あるいは大きく異なってきます。
立地条件をどのように定義するか、 どのように数値化するかで出来上がるデータは異なってきます。
それなのに、一律にこういうデータで行こうと決めつけて、
データ収集をしてしまうとそれが間違っていたような場合、
すべて、調査し直しということになります。
30店くらいだったら、
取り直しもさほど 苦ではないかもしれませんが、
数百店ではとても簡単にはできるものではありません。
少ない数から始め、どのような立地データが役立つかわかるようになってきてから
だんだんとサンプルを増やしていくことをお勧めします。
小さな店舗規模のチェーン店では、競合した時の影響があまり売上に反映されないことが多いばかりか、場合によっては、競合するほど売上が高い(競合性と売上が正の相関を示す)というような「常識と異なる」ことがひんぱんに発生します。
ところで、「説明変数のt値(ティーチ)は、1以上でなければならず、2以上が望ましい」
とされています。t値とは、変数の係数を、その標準誤差で割った値です。
どんな場合でもこのt値を見ることを忘れないようにしましょう。
ところで、
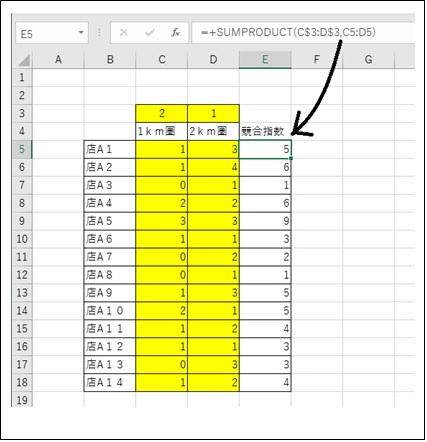
スーパーマーケットくらいの大型店になると、競合などの影響がはっきり出るものです。
ですから、例えば、半径1km圏内の競合店 および半径1~2km圏内にある競合店を数えてください。
その後、前者、半径1km圏内の店数には、a(例えば、「2」とかの定数)を掛け、後者には、b(b<a)を掛け、その和を求めます。
エクセルでやるとき、=SUMPRODUCT(A行、B行)という関数が便利です。
これは、A行にあるデータとB行にあるデータをそれぞれ掛けながら、和(合計)を求めるからです。もちろん、A行にa、bがあり、B行にデータがあります。
この関数を データの一番上の行の空いたセルに書きます。この場合、A行は、行固定をしておく必要があります。
これを、全行にわたって、コピーペーストすれば良いのです。
(以上 抜粋編 終わり)
お問合せはこちら
〒107-0062 東京都港区南青山2‐2‐15ウィン青山942
